Abstract
In recent times, severe acute malnutrition (SAM) in India is considered a serious issue as per UNICEF 2022 records. In that record, 35.5% of children under age 5 are stunted, 19.3% are wasted, and 32% are underweight. Malnutrition, defined as these three conditions, affects 5.7 million children globally. This research utilizes an artificial intelligence-based image segmentation technique to predict malnutrition in children. The primary goal of this research is to use a deep learning model to eliminate the need for multiple manual diagnostic tests and simplify the prediction of malnutrition in kids. The traditional model uses text-based data and takes more time with continuous monitoring of kids by analysing body mass index (BMI) over different periods. Children in rural areas often miss medical expert appointments, and a lack of knowledge among parents can lead to severe malnutrition. The aim of the proposed system is to eliminate the need for manual blood tests and regular visits to medical experts. This study uses the ResNet-50 deep learning model’s built-in shortcut connection to solve the image-based vanishing gradient problem. This makes training more efficient for image segmentation tasks in predicting malnutrition. The model is 98.49% accurate in predicting the kids who are malnourished among the kids who are healthy. It is evident from the results that the proposed system serves better than other deep learning models, such as XG Boost (75.29% accuracy), VGG 16 (94% accuracy), Xception (95.41% accuracy), and MobileNet (92.42% accuracy). Hence, the proposed technique is effective in detecting malnutrition and diagnose it earlier, without using predictive analysis function or advice from the medical experts.
Introduction
Malnutrition is a significant social health challenge; more than a million people are fighting for their lives and improving health disparities, particularly in resource-constrained regions. As per UNICEF reports of 2022, 5.7 million children under 5 years old suffer from a severe acute malnutrition condition called SAM. In India, 19.3% of children under the age of five suffer from malnutrition, with 35.5% being classified as stunted, 32.1% as underweight, and 19.3% as wasted. Problems with old ways of doing things include having to manually check for malnutrition (measured by Body Mass Index, or BMI), waiting longer for a diagnosis, and not having enough medical tools to check for and find malnutrition in children in rural areas. Recognizing and addressing malnutrition promptly is crucial to mitigating its severe consequences. The importance of addressing malnutrition in children cannot be overstated. Stunting, for instance, defines chronic malnutrition related to kids’ development delays and long-term abnormal health challenges. Acute malnutrition conditions are mostly caused by waste, which raises a child’s risk of death, especially in areas with limited access to health care. India’s growing population is facing big social, economic, and public health problems because of these conditions in kids younger than 5 years old1.
Traditional malnutrition diagnosis methods rely on physical measurements such as weight, height, and BMI, which are further analyzed with blood and clinical assessments. While traditional methods provide accurate data, they are a more time-consuming process and only depend on trained professionals. The trained professionals are not to be accessible in remote and rural areas where malnutrition in kids’ identification is more prevalent; furthermore, parental awareness of malnutrition is often very low in such rural areas, further increasing the malnutrition problem2.
The ResNet-based malnutrition detection model holds immense potential in healthcare facilities, where it assists clinicians in rapidly assessing a child’s nutritional status through facial images. Many communities across the country that have been researching health-related issues can adopt this technology. Valuable biometric information can be used in the face to document the body parts and their color, size, and shape. Biostatistics understands that severe acute malnutrition (SAM) and hair color serve as positive indicators of a healthy child. Inspired by current human studies, this research explores methods for classifying the affected children using a facial mapping method based on the ResNet-50. This proposed ResNet-50, a 50-layer architecture, faces image segment detection. The proposed work creates a classification to evaluate SAM, utilizing real-time images of children under 5 years old. SAM calculations can commonly resolve malnutrition. Traditional deep learning models focus on gathering predictive manual data to assess the child’s malnutrition condition. SAM estimation primarily relies on the child’s frequent hospital visits, resulting in a longer timeframe for determining the status of the child’s malnutrition. The process of estimating SAM using a child’s face has been less popular in the earlier days due to misunderstanding and lack of knowledge among the general public. To streamline the examination process and eliminate the need for manual testing, here is a process for a dataset using children’s images. This dataset includes facial information such as colorless hair, cheeks without proper muscles, and internal forehead bones, all of which we process as metadata. Researchers have conducted a facial image examination to predict malnutrition in children. In addition, this research will be considered as a new approach, and it will be applied in places where there is a lack of technology for testing children’s health issues. Furthermore, implementing this deep learning technique, which involves capturing children’s images using an available camera, will enable remote nutritional assessments and identify gaps in accessing healthcare facilities3.
The study uses the ResNet-50 deep learning model to find kids who aren’t getting enough food. This model’s best feature is that it can effectively deal with degradation problems by using a residual block with a built-in jump connection to handle the vanishing gradient problem. ResNet-50 is good at properly mapping facial features in kids’ faces. It has advanced features like quick feature extraction for finding facial abnormalities in the nasal starting point, chin pumps, and skin color, which looks at how to tell if a child is malnourished. Furthermore, the ResNet-50 is robust in identifying the variation of different facial images under various light conditions, and it accurately identifies malnutrition using facial images. Because it is a pre-trained model, it reduces training time, and the minimum computational resources were needed for implementation, making it an efficient model for predicting malnutrition in kids using static facial images. Ultimately, the residual block receives the webcam facial image to forecast the child’s malnutrition, prompting parents to visit healthcare facilities for additional treatment4,5.
According to the current well-being healthcare analysis, the kids’ malnutrition identification system needs a computational update. The present study will examine children’s facial images. There exists a close link between severe acute malnutrition and some other illnesses, so severe acute malnutrition is important for analyzing a kid’s regular dietary function. Generally, severe acute malnutrition was measured in kids with some manual testing and with a continuous hospital visit. This research explores a deep learning model that can predict a child’s image to monitor the health condition appropriately. With the wide use of the internet and the growth of AI models, people can now easily share all kinds of information. Deep learning techniques can utilize snapshots of a child’s face to assess the children’s well-being, especially in determining the state of malnourishment. This research can be considered as boundless assistance to healthcare investigators in accessing SAM data on kids and their status using images, which provides an advantage in monitoring the kids in rural, less improved, and remote locations. By installing the deep learning model on a laptop or PC with webcam access, it can effortlessly identify children suffering from malnutrition and also those who are obese, using the facial images to predict the malnutrition status. Using this model, medical practitioners can immediately analyze the obtained outcomes. Figure 1 describes the graphic representation of malnutrition in facial images by ResNet-502.

Resnet-50 based Malnutrition Facial Identification.
Objective of this research
The objectives are:
-
1.
To conduct a comprehensive literature review on the background, primary themes, and obstacles associated with detecting malnutrition in children nationwide through facial image analysis, emphasizing the use of the ResNet-50 architecture for deep learning-based classification.
-
2.
To propose an innovative ResNet-50-based malnutrition detection model that can accurately categorize Children using facial images as malnourished or non-malnourished. The primary goal is to overcome limitations in the existing models and enhance their efficiency and performance through the robust ResNet-50 architecture and layer customization, which allows deeper and more effective feature extraction.
-
3.
To conduct thorough experimentation on the proposed ResNet-50 model by evaluating crucial metrics such as detection rate, accuracy, precision, recall, false-positive rate, etc. This experimentation aims to validate the model’s effectiveness and performance in predicting malnutrition indicators using facial images.
-
4.
To perform efficient training and define comparative analysis of the ResNet-50 architecture in achieving accurate and efficient malnutrition facial classification are defined in detail for future research.
Organization of the paper
-
Section 2 provides an overall explanation of related works to malnutrition detection through manual calculation and image segmentation process to develop in ResNet-50 architecture.
-
Section 3 focuses on various methods and materials involved for classifying and detecting malnutrition using ResNet-50.
-
Section 4 explains about ResNet-50-based malnutrition detection algorithm with image segmentation, facial mapping, and formulates batch normalization mathematical calculations.
-
Section 5 provides the results of the experiments conducted on the research of the proposed model by testing and training datasets to calculate and analyze the performance metrics.
-
Section 6 concludes the research paper by summarizing the key points of the research.
Related works
Malnutrition in the kids is analyzed by using the normal body mass index by manually calculating height and weight and identifying the diet plans that are purely based on their mother’s answers about the kids’ daily routine. But conditions like marasmus and kwashiorkor, which can lead to hair that is discolored and breaks easily, muscle loss in the chin, and a dip in the upper nose, can be found by looking at the way a child’s face is shaped. Manual data analysis of the above-mentioned condition is time-consuming, and children in rural areas lack the resources to assess their level of malnutrition. Here, a proposed deep learning model to predict malnutrition in kids by examining their facial images6.
Several researchers have proposed earlier deep learning techniques to analyze malnutrition in children using facial images; however, there are some issues that exist in the prediction accuracy. In recent years, there has been an increase in the use of deep-learning artificial intelligence models to analyze images and predict the desired research output. To mitigate the level of prediction accuracy associated with image identification, it is crucial to have active methods for prediction that are likely to improve further in the future. Below, some recent works related to the research are mentioned.
As a set of data from women, Islam et al.3 suggested an ML algorithm with multinomial logistic regression and random forest. It achieves an accuracy of 82.4% in predicting malnutrition in women. However, it does not significantly outperform the deep learning image prediction method or manual data collection. Konstantakopoulos et al.5, The authors proposed an artificial intelligence system for volume estimation. Through simulation, an artificial intelligence system can detect images using a smartphone and process the image extraction to identify the dietary assessments. The test results show that the proposed AI system has a regular estimation error of 10.89% on all image data. When compared to the proposed ResNet 50 model, the prediction accuracy range for analyzing the image is 95%. In the suggested model, image segmentation goes into residual blocks, which raises the resolution of the image so that each facial image can be studied both theoretically and analytically.
Siy Van et al.7 tested how well Random Forest could use anthropometric classification to sort elementary school children who were malnourished and found that it was 78.55% accurate. This model requires a significant amount of time to analyze data from children over two months. The suggested model, ResNet-50, on the other hand, finds malnutrition by classifying faces from pictures, using severe acute malnutrition conditions in the trained face. Rahman et al.8 developed a malnutrition prediction classification that uses the Random Forest to detect malnutrition in kids under the age of 5, while detecting malnutrition with an accuracy of 88.3%. While comparing these two studies, the proposed ResNet 50 model has a high accuracy of predicting malnutrition in kids using their facial image segmentation.
Minaee et al.9 defined image segmentation using deep learning on twenty different DL models. Their study showed that the ResNet model is better at predicting the accuracy of the facial dataset than some other deep learning models, like KNN, MLP, Random Forest, Support Vector Machine, and Decision Tree. ResNet’s image segmentation is very accurate because it improves image resolution with a residual function. This makes it better than other deep learning representations at making accurate predictions.
Deepa et al.10 Ridge-Adaline Stochastic Gradient Descent with an AI model for healthcare analysis to look at image-based evaluations of healthcare data. A comparative analysis reveals that the accuracy of detecting image-oriented applications is approximately 92% compared to the traditional model. This model provides a more accurate implementation of an image-oriented approach compared to the data-oriented traditional deep learning model. Fu et al.11 suggested a stacked deconvolutional network for larger image datasets. This network is one of a kind because it can segment images with 86% accuracy, but it doesn’t do enough to fix the problem of gradients that disappear in images. After transferring more images to the convo layer, the ResNet-50 layer processes them to achieve the desired image segmentation. Later it splits the images to process the final activation function using ReLU; therefore, it overcomes the vanishing gradient and effectively reshapes the image.
Maniruzzaman et al.12 developed a hybrid model, combining logistic regression and random forest to process the classifier to identify diabetes. This method achieved an accuracy rate of 90% but resulted in a higher false positive rate when applied to different classifiers using a machine learning approach. However, many of these can lead to delays in processing the data into a model. The proposed model achieves high accuracy with a prediction of malnutrition and a higher residual block to get the desired result in quick response time. Innocent Mboya et al.13 proposed a deep learning scheme that uses machine learning to overcome predictive analysis issues. This allows the prediction of perinatal death using logistic regression detection, with an accuracy of 95%. However, the proposed ResNet 50 has feature-image segmentation using batch normalization, which helps find shapes that are not the same in the embedding image so that overfitting can be thrown out. This makes the proposed ResNet 95.2% more accurate.
VijayaKumari et al.14 developed a unique approach for mining discriminative visual components using EfficientNetB0. This approach enables EfficientNetB0 to process image segmentation uniquely, using an input of 224*224. It processes the rotation of images in a horizontal float at point 6 and then employs the pooling activation function of Softmax to achieve 80% accuracy. Still, the suggested image analysis model has both primary and secondary activation functions to keep the accuracy of facial image prediction from becoming too good. These use a reshape option from a different image to get the accuracy we want without having to rotate the image any more. Zhao et al.15 proposed a joint-learning distilled network that had a compact network training model size. This implies that the model uses simultaneous training of image data to activate a map on all points intersecting each image in the entire dataset. This model is excellent at predicting image accuracy in small datasets, though. The proposed ResNet-50 model, on the other hand, can use multiple layers to process larger datasets and achieve 98% accuracy in a dense dataset.
Talukder et al.16 used the Random Forest deep learning model to identify malnutrition in Bangladesh for under-5-year-old children. This model achieves an accuracy of 68.5% while testing with five classifiers. This helps to analyze the severe malnutrition function with a predictive collection of data, which is used for identifying nutrition-deficient kids. However, this model lacks an image segmentation process; instead, it solely utilizes word embedding functions to analyze malnutrition in children, resulting in an accuracy range of less than 70% for the RF classifier model.
In, Arslan et al.17 suggested using Ensemble ResNeXt-DenseNet and showed an ensemble model that can identify images in a large dataset while fully analyzing the width of the images with compound analysis to scale in the image. This model is excellent at doing this on a large scale. The ResNet-50 employs the same techniques to analyze the width and height of the kid’s image, enabling effective scaling to enhance the prediction accuracy of malnutrition in children. This is achieved by using facial segmentation to analyze severe acute malnutrition in children.
Bitew et al.18 proposed the xgbTree algorithm to identify malnutrition in children and had an accuracy range of 86–88%. In this case, the deep learning model performs well with children who are overweight by nature; its prediction accuracy is high. The proposed model utilizes facial image separation to extract data from the image using ResNet-50. Here, the reshaping of images is done with a different layer process, and it is suitable for identifying both overweight and underweight kids by analyzing their facial images to identify whether they are malnourished or not in a lesser time. Park et al.19 obtained the Mask R-CNN for image segmentation solution, which differs from the predictable method. Here the data of the image are analyzed and fine-tuned with different aspects of the image processed to make a synthetic training to process the image-oriented function. If the dense data is limited, it will analyze the count of the image and provide an image-analyzed accuracy of 52%. The proposed ResNet-50 model can make up for the loss in fine-tuning. It structures each image with a planned pattern of resizing the image in each layer to produce high accuracy in image identification using a deep learning model.
A study by Mani et al.20 suggested using a decision tree (DL) based on the random forest to find kids who aren’t getting enough food. The DL was 86.3% accurate, but it couldn’t predict facial expressions. Reis et al.21 use a decision tree to analyze malnutrition, achieving 91.0% accuracy and using only predictive data analysis. Kuttiyapillai et al.22 used the KNN model to test malnutrition for under-5-year-old kids in India and achieved an accuracy of 94.7%. The analysis of the results involves BMI calculations and predictive analysis, which can be a time-consuming process. Thangamani et al.23 use the MLP deep learning model and produced an accuracy of 77.17% in identifying malnutrition among kids. After analyzing all the aforementioned models, they developed ResNet-50, which uses a facial image segmentation technique to identify malnutrition in kids. This model achieves an accuracy of 95.2%, which is higher than the previously mentioned deep learning model. Additionally, it provides results much faster than the predictive manual analysis function. Above all, the proposed model does not require hospital visits to determine malnutrition status. The proposed model analyzes and validates the malnutrition prediction using a facial image of children.
Turjo and Habibur Rahman24 proposed a descriptive data analysis method focusing on women impacted by malnutrition. 45% of the descriptive data analysis identifies computations for nutritional status. Once the data analysis is complete, it can transfer the entire report to Random Forest, one of the superior machine-learning techniques that achieves 60.2% accuracy, thereby reducing the need for direct hospital visits.
Wu et al.25 proposed the use of fuzzy logic in CNN for epistasis detection. They also presented a model to interpret the genomic data with high accuracy. Similarly, the proposed model, which uses ResNet-50, employs the same techniques to analyze the width and height of the kid’s image, enabling effective scaling that can enhance the prediction accuracy of malnutrition in children. This is achieved by using facial segmentation to analyze severe acute malnutrition in children. Thakur et al.26 proposed the use of a deep learning model in diagnosing Parkinson’s disease. Also, they talked about how to use the DenseNet-121 model to find putamen regions in a large dataset of images with high scalability and soft attention maps. This model leverages the benefits of a neural network to precisely identify specific brain regions from scanned images, thereby enabling more accurate disease detection. Similarly, our study uses the kids’ facial mappings to identify the malnutrition condition with the help of the ResNet 50 deep learning model.
A study by Lu et al.27 uses a modified CNN model and a marine predator algorithm to get a score of 93.4% on the RIDER dataset for correctly predicting lung cancer. This model does a better job of predicting lung cancer than traditional models like VGG. Nanehkaran et al.28 use KNN to classify the type of disease in the patients with a given recommendation to the patient’s caretaker with the IoT device. The recommendation model performs well in health record classification with the PhysioNet dataset. Wei et al.29 conducted a study using a modified thermal optimization algorithm to predict skin cancer through image segmentation. They performed 20 different feature extractions in the initial phase to annotate the image and predict disease with high accuracy30.
One example is looking at all of the above processes together shows a unique way to analyze facial images, and it shows how well the proposed method works with a real-time dataset of children’s facial images. Many researchers have developed deep-learning techniques and methods to improve image segmentation by predicting its accuracy. Sometimes the quality of the image, such as a lowered or blurred image size, affects the training phase of the model. So, the proposed model offers numerous advantages that address all the aforementioned issues.
From the above-listed literature review, the highlights of the choice of ResNet-50 in malnutrition kid identification using static facial images are mentioned below:
-
1.
The ResNet-50 model has a skip connection, which can overcome degradation problems that are available with the traditional deep learning models. With the advantage, ResNet-50 helps in generating accurate results without suffering from vanishing gradient problems.
-
2.
ResNet-50 residual connections allow for better image extraction methods for faces, which leads to the highly accurate detection of malnutrition.
-
3.
Transfer learning enables ResNet-50’s deep architecture to distinguish between new and unseen data using a pre-trained dataset, ensuring reliable face recognition across a diverse range of demographic groups.
-
4.
ResNet-50 can identify different levels of malnutrition in children’s faces by starting with skin tone, chin structure, and nasal bone. It has an accuracy rate of 98.49%, which is the highest of any image classification model.
-
5.
It uses batch normalization to pull out image features, and its final activation function uses different residual block functions to fix the vanishing gradient problem.
-
6.
The testing and training phase ResNet-50 processes well in extracting facial image features by processing convolution, batch processing, pooling, normalization, and activation functions. It has 50 layers to produce high-quality, accurate image predictions and get the desired result.
-
7.
The L2 regularization in the ResNet-50 fixes the image overfitting problem, and the binary loss function finds the training model overfitting problem.
When the intended model tried to predict a facial image, it found some technical problems. The ResNet-50 deep learning model then fixed many of the problems. This innovative model aims to improve processing efficacy, thereby allowing well-organized and appropriate identification of malnutrition in kids under 5 by using their facial images31,32.
The summary of the research gaps identified by the existing methodologies presented in this section:
-
(a)
The traditional methods of analyzing malnutrition in kids by BMI calculations in addition to the blood sample analysis are time-consuming process and intervention of trained professional more rely on these traditional methods. But the proposed research study uses facial image segmentation for malnutrition analysis in kids which extract facial features like chin structure and the starting points of the nose to predict malnutrition which eliminates the medical expert need and traditional time-consuming process like BMI.
-
(b)
The traditional deep learning model lacks in technological integrations such as ability to provide rapid results, which needs additional data other than facial mappings. The proposed model achieves a superior effectiveness and reliability in identifying nutrition deficit kids with facial extraction feature by achieving high accurate results of 98.49% whereas traditional models like XGBoost achieves 78.29% and random forest as 82.32% lacks in detecting malnutrition in kids.
-
(c)
Traditional methods have limited focus on automation and rely more on continuous monitoring and regular hospital visits with parental compliance needed, but in rural areas awareness about the malnutrition’s are very low. The proposed study with the use of AI based medical test suitable in resource limited settings can be widely available in smartphones or basic imaging devices ensure scalability and accessibility to all kinds of people.
-
(d)
In traditional models the analysis of malnutrition’s are more dependent on healthcare workers with repeated physical test and uninterrupted monitoring process, whereas the proposed model bridging the awareness gap in rural areas with a simpler and more efficient diagnostic tool which detect malnutrition on kids at very early stage. It helps healthcare workers to assess and improve dietary practices among nutrition deficit children.
Materials and methods
As shown in the ResNet-50 model, the goal and function are planned to predict malnutrition in children by using the child’s face to sort them into two groups based on whether they are normal or not.
Dataset
The dataset for the malnutrition study is available at https://www.kaggle.com/code/masterofall/notebook1ed813e60a, and an additional face dataset is available at https://yanweifu.github.io/FG_NET_data/. The right identification of hardware and software is mandatory to train and test ResNet-50 in malnutrition detection kits. The hardware includes an Intel Core i5 13th generation processor, an Intel Iris Xe GPU with 32GB of DDR4 RAM, and an external CPU that works with Google Colab. The software stack is used for running the deep learning framework with the operating system Windows 11, TensorFlow for the training interface, the PyTorch application programming interface, and the development environment in Google Colab33,34.
The malnutrition data set is a collection of data on children suffering from various types of diseases. It was compiled by malnutrition-data-set and contains 328 various images of malnutrition in children and 3000 from FGNET facial expressions, which have all types of gender facial expressions. The facial expression of the child suffered from malnutrition is slightly different from a healthy child. The misshaped hair, nose, cheek, and other facial features provide a detailed understanding of how malnutrition affects a child’s physical appearance35.
The dataset is very important for training and validating deep learning models like ResNet, VGG, Yolo, MobileNet, and Xception to sort the facial clues that show that a child in India is malnourished. The model uses the incorrect shapes and colors of the hair, eyes, nose, and other facial characteristics as critical visual indicators, which can lead to predictions and contribute to the automated detection of malnutrition at an earlier stage. By leveraging the data set, researchers and practitioners can improve the capabilities of image classification to discern malnutrition-related facial patterns. The main goal is to develop an algorithm that can assist healthcare professionals efficiently and accurately using a clear and properly sized image dataset in detecting malnutrition among the children36,37.
With bigger datasets, ResNet-50, a generalized model, does better than models like MobilNet, Xception, and YOLO. It shows great skill in many image classification and medical imaging tasks with weights that have already been trained. Other options include MobileNet, Xception, and YOLO, all of which are good at image recognition tasks. However, ResNet-50 offers deep feature extraction with different residual blocks that accurately identify facial features associated with malnutrition in kids, while models like YOLO are hard to use because they have complicated architecture and are mostly focused on object detection tasks. With an accuracy of 98.49%, ResNet-50 is the best model for identifying malnutrition in children based on facial images. It is better than other image classification deep learning models.
As the field moves forward, machine learning engineers, data scientists, healthcare professionals, and humanitarian groups work together to help study malnutrition by setting up a camp to collect more images from different parts of the country. This makes the output more reliable with high quality38,39.
Pre-processing
Data preprocessing is an important part of the deep-learning pipeline. It entails cleaning and modifying the raw data images to ensure each one has the correct resize scale value, enabling a neural network learning model to accurately predict when a child is malnourished. The goal of the data preprocessing is to enhance the quality of the data, improve the model’s performance, and ensure that the model can learn meaningful patterns of some mathematical matrix values from the data to classify the images. A facial dataset with 3638 images of children and adults is added, with 638 of them being own facial datasets processed from https://yanweifu.github.io/FG_NET_data/. The training dataset is stored in a directory called “train,” the validation dataset is stored in a directory called “validation,” and the test dataset is stored in a directory called “test.” Each directory contains subdirectories for different classes, such as malnourished and non-malnourished40,41.
During the training phase, real-time data augmentation takes place.Image-Data-Generator Data augmentation entails applying various random transformations to the images and dynamically creating new training samples. This concept helps the model in generalization as well as possible by exposing it to a wider range of variations in the input data. The image in the datasets should be (224, 224), and it is a rescaled value. This is a common practice in the generation of images with a perfect resale value, especially when using pre-trained neural network architectures, as many models expect a fixed input size. During training, instruct the model to update based on batches of 32 or more images. This implies that the model analyzes certain mathematical expressions and learns from 32 or more images with updated weights ahead of schedule. Batch processing is well organized in terms of memory usage and computational properties. The crucial task involves training the model to differentiate between malnourished and non-malnourished facial images. The class_mode=”binary” parameter indicates that the generator is implemented for binary classification problems. The class_names variable contains the class names. During the training and testing stages, the data generators use these factors to label the images. During training, data validation is used to cross-verify the model’s performance on the image for further classification, a feature that was not available before. On the other hand, ResNet-50 uses testing data after training to see how well the model works on new image data. A flowchart in Fig. 2 illustrates the process of preprocessing42.

Representation of Preprocessing in ResNet-50.
Residual blocks
Residual blocks are the main component of residual neural networks (ResNets). The implementation of residual networks addressed the vanishing gradient problem, a significant issue that exists during the training period. Residual blocks use skip connections to train very deep neural networks, allowing the model to learn residual mappings. During the training period, the main motivation for residual block implementation is the introduction of a shortcut connection to skip one or more layers. The shortcut connection is a straightforward approach to the path from the block’s input to the output. The residual block’s main path contains one or more convolutional layers. The block finalizes its output by adding the output of the main path to the input (shortcut connection). The activation functions (e.g., ReLU) are typically implemented after each convolutional layer to introduce their non-linearity. When the skip connection is implemented, the network learns identity mapping, which is the optimal solution. Unlike other approaches, traditional architectures require the network model to learn the desired mapping from the beginning. The residual block helps to skip the vanishing gradient problem, which makes it easier to train a very deep neural network model like ResNet. Residual blocks are one of the building blocks in many deep learning architectures, especially in computer vision tasks such as complex ones like image classification and object detection. They train deeper networks, resulting in improved accuracy and generalization. The malnutrition facial detection model implements ResNet-50 as its backbone architecture. This is one of the deep neural network architectures that is selectively preferable for computer vision tasks42,43.
Classification
Using classes, the dataset categorizes facial images based on the presence or absence of malnutrition. Each facial image has a shape expression to identify the classes in the binary classification per pixel, specifically indicating whether the person depicted is malnourished or non-malnourished. The deep learning models significantly impact image classification accuracy. The different learning models available are transfer learning, federated learning, multi-task learning, and multi-valued learning. ResNet-50 employs transfer learning, a method known for its simplicity and effectiveness in image classification tasks. Other learning models, including federated learning, multi-task learning, and multi-valued learning, can demonstrate effectiveness in image classification analysis. However, their additional architectural complexity may lead to overfitting in achieving the desired accuracy. Additionally, there are constraints, such as limited data availability, limited computational resources, and significant privacy concerns. To put it simply, ResNet-50 labels each facial image as either malnourished or not malnourished so that the deep neural network model can learn to tell the difference between the two groups, no matter if the image being fed is malnourished or not44.
ResNet-50 model training
The ResNet-50 model is a pre-trained deep neural network model used to predict the labeled facial images. During the training period, the model learns to analyze and extract features from images and make predictions based on the patterns learned from the extracted facial features. The optimization process entails updating the model’s parameters using an iterative optimization procedure based on stochastic gradient descent45,46,47.
Initial layer
The convolutional layer receives a sequence of arguments as involvement. By filling the 3*3 matrix of coloured images processed into the convo layer, every image in the matrix signifies an expression feature quarried from the filter. Numerous convo filters of several dimensions are utilized to process normalization. The input image is denoted as I, and the image size is denoted as S, P for pooling, and Tr as stride. The formulation for calculating Convo matrix I’ is given as Eq. (1)48,49.
Proposed ResNet-50
ResNet’s performance makes it a powerful deep-learning network model. In fact, ResNet works like a CNN because it has many convolutional layers and extra blocks that are left over after training a deep neural network model. This makes it more flexible and faster. In the schematic diagram analysis, the proposed ResNet-50 combines different parts that can work together with the system to make it better at using kids’ faces to find kids who aren’t getting enough food. Initially, a residual block is embedded in a CNN architecture for deep training without being affected by the vanishing gradient problem. The 50-layer depth makes sure that facial mapping can be found in the shape of the chin and cheeks, as well as the nasal bone structure, which is called the “region of interest” for ongoing analysis. There are four stages in the model: max pooling, batch normalization, dropout, and average pooling. These are used to capture the spatial features. The Adam optimizer and skip connection handle the optimization, enhancing gradient flow, while the L2 regularizer guards against overfitting. Finally, the output layer segments facial images into a meaningful feature representation. This schematic architecture enables precise malnutrition detection in kids with minimum false negatives50,51. Schematic architecture representation of proposed model is expressed in Fig. 3.

Schematic representation of ResNet-50.
Residual block
Integrate residual blocks into the basic CNN architecture. The existing convolutional layers are replaced with residual blocks. The residual blocks are very important for training the deeper networks because they help with the vanishing gradient problem by starting with weight zero and two shortcut connections to deal with conditions that don’t change.
Architecture depth
The concept of data preprocessing is a crucial step in the network’s depth analysis. ResNet architectures have versions like ResNet-18, 34, and 50. The number of layers in the classification process is shown by the model’s suffix, and the ResNet suffix tells you about their batch normalization function, which works with different layers to get accurate results. ResNet neural networks may be very helpful in capturing features, but they can also take less computational time to generate accurate results.
ResNet-50 annotation marking
ResNet-50 processes the marking of facial images using the facial region of interest annotation, which identifies specific facial regions, such as the chin, cheeks, and nasal bone structure, as indicators of malnutrition in children during the training phase of the model. Importing annotations for malnutrition and non-malnutrition facial features ensures consistency in analyzing image abnormalities. Final validation is processed with multiple annotations, such as a single facial image of kids that captures different postures associated with malnutrition. These postures’ analysis, including facial bones at the nasal starting point and skin color, accurately predicts malnutrition in normal children. In this case, the evidence theory is used as the basis of the Dempster-Shafer theory in artificial intelligence to deal with uncertainty and make the proposed model a valid model. This is done with a better marking scheme and a conservative threshold that handle the worst-case scenario validation so that no pictures of malnourished kids are missed, which lowers the number of false negatives for the proposed ResNet-50.
Training
Training a model involves combining an architecture, a perfect optimization algorithm, and a loss function for a specific task such as classification, object detection, or segmentation. Techniques such as batch normalization, dropout, and data augmentation are used to enhance the simplification and convergence of the model in terms of accuracy rate. In a ResNet-50 architecture model, the global average of the max pooling layer plays a vital role. The collection of spatial information primarily captures the preceding convolutional layers, processing orthogonal initialization to the next layer.
Optimization and weighting factor
To get around the problems with binary classification, one can use binary cross-entropy loss to get the best result without losing a lot of information in prediction analysis. The stochastic gradient descent, or Adam as an optimizer, is commonly used for model optimization to identify whether image reshaping happened or not and then move the result to the final layer. Skip connection residue blocks select the weighting factor in the proposed ResNet-50. The grid search approach is used by selecting data manually and processing different combinations, and the performance is validated. ResNet-50 is good at solving the vanishing gradient problem using gradient-based optimization and an Adam optimizer that changes the weight and tries to minimize the loss with its learning rate. L2 ridge regularization is also used to keep the proposed model from fitting too well and fix issues with the weighting factor. With all these various considerations, the model is fine-tuned to achieve optimal performance in predicting malnutrition in kids with static facial images. Based on our datasets and image processing tasks, fine-tune the combination of architectures. Hyperparameters are adjusted, and tuning the model leads us to experiment with the network architecture to achieve optimal performance42.
Facial image segmentation process
Different sizes of residual layers are used to mine different kinds of local information. The symbols H(x) initialization and X stand for the mapping function, F(x) residual function, and input layer of a face image, respectively. Equation (2) provides the formula for calculating the linear projection of the input face image42,52.
Using the weight of the input face image W(x), statistics on image mapping can be compiled. Each residual mapping of the image has to define the optimization of the nonlinear layer in the input face image and after the convolution function. The following Eq. (3) is for the ResNet block.”
Equation (4) expresses the state of a weighted pair of face images, where W1 signifies the weight of input image 1, W2 signifies the weight of input image 2, Xn for n-number residual face images, and Relu for the initial activation function.”
Equation (5) is used to calculate the initial activation block of each layering function of the facial image using the mapping function H(x), where x represents the normalization of each residual block image and F(x) residual function.
Computing all the facial images in Resnet by processing the sum of each residual block without altering the final output image face shape is mentioned with Xk, Yk, and Wk, where k represents the shape of the image in the residual block in equations Eqs. (6) and (7). The summation of the residual block to k + 1 as shaping is done with the batch normalization function.”
Each stage in the Residual Block of ResNet-50 is expressed in Fig. 3.
Output generation
In Eq. (8), the weighted value k appears in the context of the weighted value n representing the total number of face layers. Images are typically scanned in all residual blocks, which aids in avoiding the change of the original face image.
Equation (9) contains the formula for determining the count of feature pooling. Face image split for identity Face image mapping is present in the model as Xk+1= Yk.
Equations (10), (11), (12), (13), (14), and (15) all mention ResNet output and picture retrieval. In the following equation, Wn denotes weighted image input, and Xk indicates the change of the residual block. Yk denotes the padding of images in a serious, activation Relu function before the softmax layer, represents the final face image process before the final activation function, ⊙ combines different reshapes of output face images from each residual block42.
The activated residual network improves accuracy calculation as mentioned in Eq. (15). The final activation layer from residual output is transferred to sigmoid H and z rotation, where Y and X represent the final block output. It is shown in Eq. (16), and the sigmoid activate function to differentiate between normal and abnormal malnutrition using face mapping is mentioned in Eq. (16).
The predicted output of ResNet 50 network is indicated as H(X). It transfers first from pooling layer to softmax, n are different residual blocks, Loss function is used to solve the vanishing problem and Wn as transformation path Wkn as weighted value and(::lambda::constant), L2 regularization used to Fix the overfitting in the training model of ResNet is clearly defined in Eqs. (17), (18), (19) and (20).
The algorithm for Malnutrition Prediction ResNet-50is discussed below53.

Malnutrition Prediction ResNet-50.
Experimentation and results
In the malnutrition face-detection model, each layer of the ResNet processes the packets representing facial features. The deep neural network architecture fixes the issue of each residual block’s vanishing gradient by adding new features and continuously sending packets with important local data into the system so that the activation function can identify the data. Figure 4 expresses the representations in the facial data that the ResNet model excels at capturing54.

Malnutrition face detection workflow.
Structure and parameter of ResNet-50 and its advantages over available traditional model:
ResNet-50 is neural network used to train large datasets by very deep networks with residual connections to overcome vanishing gradient problem. The shortcut connections allow to learn from residual function instead of directly mapping the input and output.
-
(1)
The structure of ResNet-50 includes a convolutional layer with 7 × 7 followed by max pooling layer, consisting of three filter of sizes 1 × 1, 3 × 3 and 1 × 1 to reduce computational cost with intermediate layer.
-
(2)
The residual blocks to address the vanishing gradient problem to maintain effective training of very deep networks.
-
(3)
Batch normalization to stabilize and accelerate the training across all batches.
-
(4)
Global average pooling reduces the spatial dimensions avoid overfitting by reducing the parameters.
-
(5)
Fully connected layer to serve as classifier and dense layer to mapping binary classification as malnourished or normal.
-
(6)
Final Relu activation is to compute probabilities for classification.
Experimental setup
Multiple residual blocks make up the ResNet model. Each residual block consists of multiple convolutional layers and skip connections. Skip connections are one of the architecture’s key concepts, which allows the model to learn residual mappings, facilitating deep network training. The malnutrition face detection workflow is discussed below34,42.
Input processing
The input of the Resnet model is a facial feature of the malnourished face, which is classified as layer by layer.
Residual block
Residual blocks in the ResNet architecture process the facial data as input, capturing intricate facial features and patterns.
Hidden state extraction
The hidden states are obtained by using ResNet networks as the facial expressions in the packet are processed.
Combination of hidden States
The final hidden state of the ResNet neural network model is combined to form the final representation of the facial packet’s shortcut linear networks where all the activation roles of uniqueness mappings.
Output prediction
The final representation of the facial packet is passed through an attention layer and the output layer for malnutrition face detection. This face detection model for identifying malnutrition, based on the Resnet architecture has been proved as an effective model in capturing facial features and patterns associated with the malnutrition face of a child from left (l) to right (r) where l is for calculating optimal loss and r for calculating optimal solution of the Resnet. The model’s ability to handle such complex deep networks and learn intricate representations makes it a robust tool for facial data analysis. The whole workflow is represented in Fig. 4.
Results
The final dataset that was made available is made up of 3628 real data points of facial images that show how long the model trained and tested. Here multitudes of facial image sets were used to maintain balance between two distinct classes of malnourished and non-malnourished children. Numerous comparative analyses were conducted to evaluate the presentation of the projected system, as outlined in Table 1. Figure 5 represents the confusion matrix55.
The ResNet-50 has been utilized in this research over other traditional models because of its superior performance and its effective training of deep networks using skip connections. Compared to the other traditional deep learning models, this ResNet-50 skip connection bypasses all layers and allows gradients to propagate properly. Compared to other models, ResNet-50 is better at extracting complex features from images of children’s faces, which makes it better at finding facial abnormalities. Additionally, ResNet-50 reduces the amount of work that needs to be done by adding bottleneck blocks that models like VGG16 don’t have. Finally, the easy customization for different datasets and classification tasks makes it more reliable and accurate in detecting malnutrition. All the parameter analyses of the traditional deep learning model are expressed in Table 2.

Confusion matrix.
Accuracy
Accuracy is a basic metric used to calculate the overall performance of the defined model to identify a kid’s facial images as malnourished. Moreover, the calculation for accuracy is the ratio of correctly predicted cases to the total number of available cases. If the accuracy score is high, the proposed model has a satisfactory prediction rate across the available dataset. The accuracy comparison with some existing models in Fig. 6 shows the accuracy range of some traditional deep learning models.

Accuracy.
Precision
The defined model uses precision, a basic metric, to predict positive instances and identify children’s facial images as malnourished. If the precision score is high, the proposed model has a lower range of false positive rates, reducing the chances of miscalculation across the available dataset. The precision comparison with some existing models in Fig. 7 shows the precision range over some traditional deep learning models.

Precision.
Recall
Recall is a basic metric used for calculating the correct identification of all positive instances of malnutrition in kids within the available dataset. If the recall score is high, the proposed model has a lower rate of false negatives, which minimizes the chance of missing actual malnutrition cases across the available dataset. The recall comparison with some existing models in Fig. 8 shows the recall range over traditional deep-learning models.

Recall.
ROC
The figure presents the ROC curve as a balance between true positive rates and false positive rates at different threshold classifications. In addition, it provides insights into the model’s performance across different operating points. The AUC-ROC measures a model’s overall performance by demonstrating its ability to distinguish between malnourished and healthy facial images across various thresholds. These performance metrics are crucial for explaining the robustness and reliability of our ResNet malnutrition facial detection model. The full evaluation lets us compare the model to other systems in a meaningful way and gives us a new perspective on what it can do. Next, comparing the AUC of the model to some other models (Fig. 9), which shows the AUC range over traditional deep learning models.

ROC.
F1 score
The F1 score uses metrics to show both precision and recall, and it gives a rough idea of how well the model works when the data set isn’t balanced. It balances the trade-off between precision and recall, providing a holistic evaluation of the model. The F1 comparison with some existing models in Fig. 10 shows the F1 range over a few traditional deep learning models.

F1-measure.
Overall performance comparison
Overall performance is analyzed with 60% of the data as facial data, 20% as validation data that lets hyperparameters make decisions without overfitting, and 20% as test data for the final evaluation. These ratios provide a fair and standard evaluation of the proposed model compared with the other available models like Xception, Yolo, and MobileNet. Figure 11 displays the epochs of various models, including Xception, Yolo, and MobileNet with ResNet-50. Figure 12 shows the training and test results of different models, such as Xception, Yolo, and MobileNet with ResNet-50, when using facial images to find children who are malnourished56,57.
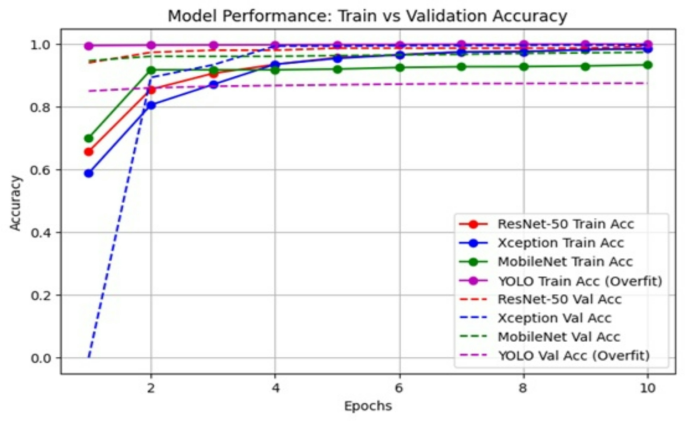
The epochs of the different model such as Xception, Yolo, Mobile-Net with ResNet-50.

The training and test results with different model such as Xception, Yolo, Mobile-Net with ResNet-50 in malnutrition kid detection using facial images.
Here, the suggested system defined the decision to use ResNet-50 rather than YOLO. YOLO has high accuracy in object detection in real-time applications, whereas ResNet-50 has high efficiency in image classification, making it a priority in detecting malnutrition in static facial images. Furthermore, the YOLO architecture is more complex and requires high-memory computational resources, making it more expensive than ResNet-50. Lastly, ResNet-50 used transfer learning with pre-trained weights in skip connections to quickly handle large datasets like ImageNet in image classification tasks. It may also be able to use feature extraction to find facial abnormalities in kids that are caused by malnutrition for medical reasons.
K-fold comparison
A K-fold cross-validation test with five equal folds for the training and testing phases is used to see how reliable the ResNet-50 model is in the process of malnutrition in kids. The final k-fold results show that the ResNet-50 consistently providing better results than the traditional deep learning model. It has an average accuracy of 98.49% across all five folds with the least amount of variation, which makes it more stable and effective at generalizing the results. MobileNet and Xception become more complicated during the folding process, while Random Forest and XG Boost make only a few extracts of features. ResNet-50 is a useful model for extracting and segmenting facial images. The unique characteristics of ResNet-50 include a residual learning mechanism that prevents the vanishing gradient problem, skip connections that enhance training efficiency, and robust feature extraction that facilitates the identification of abnormalities in children’s faces, allowing for superior classification performance in malnutrition detection. The Fig. 13 explains the K-Fold validation results of ResNet-50 against other traditional models58.

K-fold comparison of ResNet-50 with another existing model.
Computational flops comparison
Finding the number of floating-point operations per second (FLOPS) for various models lets you compare how efficiently they use computing power. ResNet-90 has good balancing computational cost and total flops to run the available dataset, which is 10,021,496,192, with detecting accuracy in the range of 98%, which is higher when compared with other deep learning models. YOLO has low computational flops in the range of 8,257,536,000. MobileNet has a lower floating-point operation per second, more in the range of 8,697,946,304 inference time as 380 ms, but it only achieves low accuracy in facial image classification. Finally, Xception has reasonable and high computational FLOPS of 9,327,101,952. According to the analysis, higher computational flops allow us to train faster and to handle large datasets effectively for the desired results. ResNet-50 has high computational flops and is a suitable model for malnutrition detection in children with facial images. Figure 14 shows how ResNet-50’s computational FLOPS compare to those of other models, and Table 3 shows how the available model’s computational FLOPS compare to ResNet-50’s using the same dataset58.
The following highlights the significance of the ResNet-50 results: ResNet-50 was the most accurate of the new models like MobileNet, YOLO, and Xception. This means that it is better at extracting and analyzing the complex facial features of children to diagnose malnutrition. This result is also important because it shows that residual connections can be used in medical health diagnostics. This model has the potential to classify malnourished children by reducing reliance on traditional medical diagnostic methods. Table 4 presents ResNet-50 significance over other deep learning models using the same dataset.

Computational Flops of ResNet-50 with another Existing model.
Proposed model outcome analysis
The proposed study carefully compares the suggested model ResNet-50 to other well-known models, checking how well it could use static facial images to spot children who do not get enough food. The data fits into three categories: training, validation, and testing. This model also works with a 32-bit batch size, a 0.0001 Adam learning rate, and 100 iterations to look at a facial dataset with 3638 pictures of kids and adults’ faces, including 638 of their own. https://yanweifu.github.io/FG_NET_data/ is the source of this dataset48. The dataset labels 1638 facial images as malnutrition and 2000 as non-malnutrition, each with a resolution of 128 × 128, in JPEG format to ensure uniformity. For model evaluation, the dataset was split into three parts: 60% training with 2182 facial images, 20% validation with 728 facial images, and 20% testing with 726 facial images. The dataset was then shuffled to use all of the available data. Quality checks are processed for low-resolution images, and malnutrition kid faces are labelled as 0 for non-malnutrition and 1 for malnutrition. In addition, using L2 regularization at 0.5 for a fully connected layer model made it more robust with rotation to a certain extent. Finally, a Python data loader loads the data, enabling the proposed model to undergo training and testing on the available dataset. Figure 15 shows validation testing in IDE. The ratio of testing, training, and validation is set at 60:20:20, using L2 regularization to adjust the weights of the facial image. The preprocessing variation of the 64 × 64 × 3 image employs the ResNet 50 model. Results are rated based on the activation function of the final layer. The layer separation size is sent to the next layer size of a 1*112*112*64 color image, which has 224 depths and a stride of 2 for the sigmoid final layer activation function. This is done to find malnutrition59.

Training and validation graph for ResNet-50.
Outcome comparison of ResNet-50
With a test rate of 1 × 10−3, the output is processed across 100 epochs for a specified total number of facial images. Input image size is 64 × 64, padding is 3, 3 kernel value is 7 for color images with the stride 2 function, then the next residual layer process height is 230, the impact is 224, and width is 230. Finally, the loss is reduced by using L2 regularization, which solves the degradation problem. Resnet-50 exhibited a greater accuracy of 98.49% with a loss of 0.03%. Table 5; Fig. 16 Comparison of the Proposed System with Traditional Deep Learning model in predicting malnutrition as shown below60,61.

Comparison of Proposed and Existing traditional DL methods for Prediction malnutrition in kids.
Using different facial annotations makes it a good pre-trained model for predicting malnutrition. Using skip connections gets around the degradation problem, which is useful, and making custom changes to residual blocks makes it a flexible model. Finally, its deep architecture makes it a specialized model to learn complex features and detect the desired signs of malnutrition in facial images.
Conclusion
The conclusion of the malnutrition investigation marks a significant breakthrough in detecting malnutrition in a child using face images. Introducing the ResNet 50 architecture as a facial detection model to analyze whether a child is malnourished or nourished, thereby maximizing the performance and efficiency with related speed and accuracy. The ResNet-50 is excellent at getting accurate images of kids’ faces by separating each facial mapping that is linked to malnutrition conditions in the child’s face. It is also a better way to show which malnutrition conditions are normal and which ones are not. There are four steps in the ResNet 50 model process: The first step involves preprocessing the dataset for face detection. Next, train ResNet-50 on the gathered faces to distinguish each face area from the SAM condition estimation model. Lastly, the system constructs standards based on the color and orientation of the face to forecast malnutrition. Then the proposed model classifies the children and shares their details with the parents for further treatment. Results obtained are suggestively high, with an inspiring detection rate of 98.4% and an outstanding low false alarm rate (FAR) of 0.07%. These accomplishments highlight the model’s efficiency in generating a well-organized and rapid malnutrition detection model as a significant advancement in the field. Upcoming research will focus on learning about possible problems and teaching cases where the model might not work very well, confirming that it is a complete and reliable model for finding malnutrition.
The proposed model opens avenues for continued exploration and improvement. In the future, researchers may look into using different deep learning methods, such as convolutional neural networks and graph learning models, to make the malnutrition detection model even more accurate and useful. Adding extra features by taking out as many features from the facial level as possible, like facial landmarks and expressions, could also give useful information and improve the model’s ability to spot malnutrition. As this research continues, the current method will be expanded by looking into feature engineering and using information from different datasets to make the model better at making predictions. Future research will also focus on the ResNet model’s resilience to potential adversarial attacks. The current research goal is to create a real-time app using the suggested ResNet-50-based malnutrition facial detection model to improve medical technology and look into child malnutrition across the country. The proposed model’s limitations include its reliance on children’s facial images. However, if the child’s face lacks visible signs of malnutrition, it processes it solely through clinical representation. This results in a longer inference time for ResNet-50, but the selection of this model ensures high accuracy. Manual correction can resolve labeling issues, potentially impacting the performance of the proposed model in future work. The suggested method takes this limitation into account more carefully in order to get high accuracy while lowering the costs of computation and development for real-time clinical applications. This makes the suggested ResNet-50 model more useful overall. In the future, researchers will test the model’s abilities on bigger datasets and more varied facial images to make sure it can work in a wide range of situations and with different groups of people. For example, they will look at how well it can predict malnutrition based on the different types of facial features of people around the world64,65.
Data availability
The datasets used and/or analysed during the current study are available from the corresponding author on request.
References
-
United Nations Children’s Fund (UNICEF). Malnutrition Report. https://data.unicef.org/topic/nutrition/malnutrition/ (2022).
-
WHO & Malnutrition Report. https://www.who.int/news-room/fact-sheets/detail/malnutrition (2021).
-
Islam, M. et al. Application of machine learning based algorithm for prediction of malnutrition among women in Bangladesh. Int. J. Cogn. Comput. Eng. 3, 46–57 (2022).
Google Scholar
-
Anku, E. K. & Duah, H. O. Predicting and identifying factors associated with undernutrition among children under five years in Ghana using machine learning algorithms. Plos One. 19(2), e0296625 (2024).
Google Scholar
-
Konstantakopoulos, F. S. et al. A review of image-based food recognition and volume Estimation artificial intelligence systems. IEEE Rev. Biomed. Eng. 17, 136–152 (2023).
-
Ramón, A. et al. eXtreme gradient Boosting-based method to classify patients with COVID-19. J. Investig. Med. 70(7), 1472–1480 (2022).
Google Scholar
-
Van, V. T. et al. Predicting undernutrition among elementary schoolchildren in the Philippines using machine learning algorithms. Nutrition 96, 111571 (2022).
Google Scholar
-
Rahman, S. M. et al. Investigate the risk factors of stunting, wasting, and underweight among under-five Bangladeshi children and its prediction based on machine learning approach. Plos One. 16(6), e0253172 (2021).
Google Scholar
-
Minaee, S. et al. Image segmentation using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 44(7), 3523–3542 (2021).
Google Scholar
-
Deepa, N. et al. An AI-based intelligent system for healthcare analysis using Ridge-Adaline stochastic gradient descent classifier. J. Supercomputing. 77, 1998–2017 (2021).
Google Scholar
-
Fu, J. et al. Stacked deconvolutional network for semantic segmentation. IEEE Trans. Image Process. (2019).
-
Maniruzzaman, M. et al. Classification and prediction of diabetes disease using machine learning paradigm. Health Inform. Sci. Syst. 8, 1–14 (2020).
Google Scholar
-
Mboya, I. B. et al. Prediction of perinatal death using machine learning models: a birth registry-based cohort study in Northern Tanzania. BMJ Open. 10(10), e040132 (2020).
Google Scholar
-
VijayaKumari, G., Vutkur, P. & Vishwanath, P. Food classification using transfer learning technique. Glob. Transit. Proc. 3(1), 225–229. (2022).
-
Zhao, H. et al. Jdnet: A joint-learning distilled network for mobile visual food recognition. IEEE J. Selec. Topics Signal Process. 14(4), 665–675 (2020).
Google Scholar
-
Talukder, A. & Ahammed, B. Machine learning algorithms for predicting malnutrition among under-five children in Bangladesh. Nutrition 78, 110861 (2020).
Google Scholar
-
Arslan, B. et al. Fine-grained food classification methods on the UEC food-100 database. IEEE Trans. Artif. Intell. 3(2), 238–243 (2021).
Google Scholar
-
Bitew, F. H., Corey, S. & Nyarko, S. Machine learning algorithms for predicting undernutrition among under-five children in Ethiopia. Public Health. Nutr. 25(2), 269–280 (2022).
-
Park, D. et al. Deep learning-based food instance segmentation using synthetic data. 18th International Conference on Ubiquitous Robots (UR) 499–505 (IEEE, 2021).
-
Mani, J. J. S. & Rani Kasireddy, S. Population classification upon dietary data using machine learning techniques with IoT and big data. InSocial Network Forensics, Cyber Security, and Machine Learning. Springer Briefs in Applied Sciences and Technology. Springer, Singapore. https://doi.org/10.1007/978-981-13-1456-8_2 (2019).
Google Scholar
-
Reis, R. et al. Machine learning in nutritional follow-up research. Open. Comput. Sci. 7(1), 41–45 (2017).
Google Scholar
-
Kuttiyapillai, D. & Ramachandran, R. Improved text analysis approach for predicting effects of nutrient on human health using machine learning techniques. IOSR J. Comput. Eng. 16(3), 86–91 (2014).
Google Scholar
-
Thangamani, D. & Sudha, P. Identification of malnutrition with use of supervised datamining techniques–decision trees and artificial neural networks. Int. J. Eng. Comput. Sci. 3(09), (2014).
-
Turjo, E., Ahmed & Md Habibur Rahman. Assessing risk factors for malnutrition among women in Bangladesh and forecasting malnutrition using machine learning approaches. BMC Nutr. 10(1), 22 (2024).
Google Scholar
-
Wu, X. et al. A novel centralized federated deep fuzzy neural network with Multi-objectives neural architecture search for epistatic detection. IEEE Trans. Fuzzy Syst. (2024).
-
Thakur, M. et al. Soft attention based densenet model for Parkinson’s disease classification using SPECT images. Front. Aging Neurosci. (2022).
-
Lu, X. Nanehkaran, and Maryam Karimi Fard. A method for optimal detection of lung cancer based on deep learning optimized by marine predators’ algorithm. Comput. Intell. Neurosci. 1, 3694723 (2021).
Google Scholar
-
Wei, L. et al. An optimized method for skin cancer diagnosis using modified thermal exchange optimization algorithm. Computational and Mathematical Methods in Medicine (2021).
-
Nanehkaran, Y. A. et al. Anomaly detection in heart disease using a Density-Based unsupervised approach. Wirel. Commun. Mob. Comput. 1, 6913043 (2022).
-
Nanehkaran, Y. A. et al. Diagnosis of chronic diseases based on patients’ health records in IoT healthcare using the recommender system. Wireless Communications and Mobile Computing (2022).
-
Hassan, E. et al. A quantum convolutional network and ResNet (50)-based classification architecture for the MNIST medical dataset. Biomed. Signal Process. Control. 87, 105560 (2024).
Google Scholar
-
Senior, A. W. et al. Improved protein structure prediction using potentials from deep learning. Nature 577(7792), 706–710 (2020).
Google Scholar
-
https://github.com/ghostmander/Healthcare-Project
-
https://www.kaggle.com/code/masterofall/notebook1ed813e60a
-
Kirk, D. et al. Machine learning in nutrition research. Adv. Nutr. 13(6), 2573–2589 (2022).
Google Scholar
-
Xu, Z. et al. Non-small cell lung cancer classification and detection based on CNN and attention mechanism. Biomed. Signal Process. Control. 77, 103773 (2022).
Google Scholar
-
Wang, W. et al. A review on vision-based analysis for automatic dietary assessment. Trends Food Sci. Technol. 122, 223–237 (2022).
Google Scholar
-
Mansouri, M. et al. Deep learning for food image recognition and nutrition analysis towards chronic diseases monitoring: A systematic review. SN Comput. Sci. 4(5), 513 (2023).
Google Scholar
-
Yang, J. et al. Medmnist v2-a large-scale lightweight benchmark for 2d and 3d biomedical image classification. Sci. Data. 10(1), 41 (2023).
Google Scholar
-
Suwannaphong, T. et al. Parasitic egg detection and classification in low-cost microscopic images using transfer learning. SN Comput. Sci. 5(1), 82 (2023).
Google Scholar
-
Minija, S., Jasmine & Sam Emmanuel, W. R. Food recognition using neural network classifier and multiple hypotheses image segmentation. Imaging Sci. J. 68(2), 100–113 (2020).
Google Scholar
-
Kumar, S. et al. Protecting medical images using deep learning fuzzy extractor model. Deep Learning for Smart Healthcare 183–203 (Auerbach, 2024).
-
Nawaz, M. et al. CXray-EffDet: chest disease detection and classification from X-ray images using the efficientdet model. Diagnostics 13(2), 248 (2023).
Google Scholar
-
Awad, F. H., Murtadha, M., Hamad & Alzubaidi, L. Robust classification and detection of big medical data using advanced parallel K-means clustering, YOLOv4, and logistic regression. Life 13(3), 691 (2023).
Google Scholar
-
Gupta, H. et al. Comparative performance analysis of quantum machine learning with deep learning for diabetes prediction. Complex. Intell. Syst. 8(4), 3073–3087 (2022).
Google Scholar
-
Li, Y. C. et al. A quantum deep convolutional neural network for image recognition. Quantum Sci. Technol. 5(4), 044003 (2020).
Google Scholar
-
Pal, A. et al. Undernutrition and associated factors among children aged 5–10 years in West Bengal, India: a community-based cross-sectional study. Egypt. Pediatr. Association Gaz. 69, 1–12 (2021).
Google Scholar
-
https://yanweifu.github.io/FG_NET_data/
-
Louridi, N. et al. Machine learning-based identification of patients with a cardiovascular defect. J. Big Data 8, 1–15 (2021).
-
Kumar, S. et al. Application of hybrid capsule network model for malaria parasite detection on microscopic blood smear images. Multimed. Tools Appl. 1–27 (2024).
-
Jaskari, J. et al. Machine learning methods for neonatal mortality and morbidity classification. Ieee Access. 8, 123347–123358 (2024).
Google Scholar
-
Shahid, N., Rappon, T. & Berta, W. Applications of artificial neural networks in health care organizational decision-making: A scoping review. PloS One 14(2), e0212356 (2019).
Google Scholar
-
Momand, Z. et al. Data mining-based prediction of malnutrition in Afghan children. 12th International Conference on Knowledge and Smart Technology (KST) (IEEE,2020).
-
Ngiam, K., Yuan & Khor, W. Big data and machine learning algorithms for health-care delivery. Lancet Oncol. 20(5), e262–e273 (2019).
Google Scholar
-
Targ, S., Almeida, D. & Lyman, K. Resnet in resnet: Generalizing residual architectures. arXiv preprint arXiv:1603.08029 (2016).
-
Elazab, N., Gab-Allah, W. A. & Elmogy, M. A multi-class brain tumor grading system based on histopathological images using a hybrid YOLO and RESNET networks. Sci. Rep. 14(1), 4584 (2024).
Google Scholar
-
Salim, F. et al. DenseNet-201 and Xception pre-trained deep learning models for fruit recognition. Electronics 12(14), 3132 (2023).
Google Scholar
-
Salim, R., Wulandari, M. & Calvinus, Y. Weapon detection using SSD MobileNet V2 and SSD resnet 50. AIP Conference Proceedings Vol. 2680. No. 1 (AIP Publishing, 2023).
-
Yarlagadda, S. et al. Saliency-aware class-agnostic food image segmentation. ACM Trans. Computi. Healthc. 2(3), 1–17 (2021).
-
Morgenstern, J. et al. Predicting population health with machine learning: a scoping review. BMJ Open. 10(10), e037860 (2020).
Google Scholar
-
Nguyen, H. T., Chong-Wah & Ngo Terrace-based food counting and segmentation. Proceedings of the AAAI Conference on Artificial Intelligence Vol. 35. No. 3 (2021).
-
Alves, L. et al. Assessing the performance of machine learning models to predict neonatal mortality risk in Brazil, 2000–2016. medRxiv 2020-05 (2020).
-
Bitew, F. H. et al. Machine learning approach for predicting under-five mortality determinants in Ethiopia: evidence from the 2016 Ethiopian demographic and health survey. Genus 76, 1–16 (2020).
Google Scholar
-
Laatifi, M. et al. Machine learning approaches in Covid-19 severity risk prediction in Morocco. J. Big Data. 9(1), 5 (2022).
Google Scholar
-
Rezaeijo, S. et al. Detecting COVID-19 in chest images based on deep transfer learning and machine learning algorithms. Egypt. J. Radiol. Nuclear Med. 52(1), 1–12 (2021).
Google Scholar
Acknowledgements
We thank, VIT Bhopal University (SPEAR), Symbiosis Institute of Computer Studies and Research (SICSR), Symbiosis International (Deemed University), and KPR Institute of Engineering and Technology for their constructive support in processing this research.
Author information
Authors and Affiliations
Contributions
All authors equally contributed to the manuscript. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
Reprints and permissions
About this article
Cite this article
Aanjankumar, S., Sathyamoorthy, M., Dhanaraj, R.K. et al. Prediction of malnutrition in kids by integrating ResNet-50-based deep learning technique using facial images.
Sci Rep 15, 7871 (2025). https://doi.org/10.1038/s41598-025-91825-z
-
Received: 04 January 2025
-
Accepted: 24 February 2025
-
Published: 06 March 2025
-
DOI: https://doi.org/10.1038/s41598-025-91825-z
Keywords
- Deep learning models
- Facial image normalization
- Image segmentation
- Malnutrition
- Predictive data analysis
- ResNet-50
发表回复